
PROPOSED PROJECTS

Unlike humans, algorithms are not very successful in recognizing objects when only part of the object is observed. Recently, we investigated the minimal size patch that is sufficient for recognition. We constructed an algorithm (a deep architecture) that could find such patches. We found however that the patches obtained in our study are usually smaller than those required by humans. The goal of the proposed research project is to settle this difference. We hypothesize that the difference is due to the small number of object categories considered in our experiments. One direction to resolve the difference is thus to increase the number of categories. Another is to uses open class recognition algorithm, that considered an infinite number of classes.
Contact:
Thomas Dages: thomas.dages@cs.technion.ac.il
Prof. Michael Lindenbaum: mic@cs.technion.ac.il
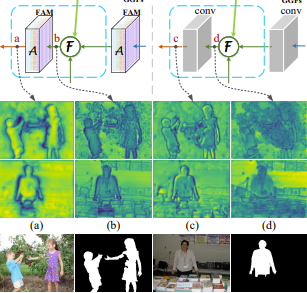
Image segmentation algorithms are useful for many applications (for example, identifying the area of a car in an autonomous driving algorithm).
In this project, we will explore one of the advanced algorithms, PoolNet. We will train a deep learning model based on the PoolNet paper .
You will gain experience in training deep learning models for computer vision in general and segmentation in particular.
Contact:
Noy Shargal noy.shargal@campus.technion.ac.il

This project focuses on the registration and alignment of a 3D virtual model onto a physical surface using Mixed Reality (MR) technology. The user selects four points on a real-world plane, and the system computes the optimal transformation—comprising rotation and translation—to accurately position the virtual model onto the corresponding physical surface in real time.
Software & Hardware
1. We shall use Oculus Quest 3
2. MR will used via passthrough
3. UNITY framework is recommended but not a must
Contact:
Boaz Sternfeld boazs@cs.technion.ac.il