
PREVIOUS PROJECTS
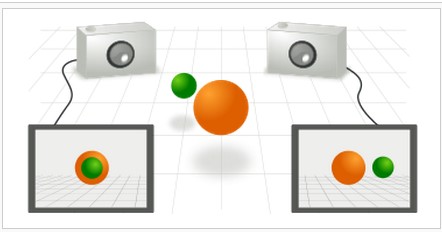
Finding corresponding points on two cameras watching the same view from different positions.

A new robot is being developed in the robotics lab. The robot’s goal is transfering specific owers in a greenhouse from one place to another. The robot is being developed on a Turtlebot paltform which is equipped with a Kinect and runs on ROS.
Our goal was to create a flower detector and reconginer as a ROS node, which can be be easily used by the team who developes the robot.
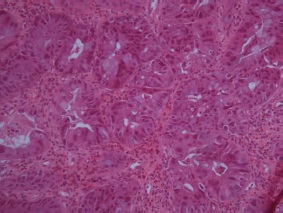
The project’s goal was developing an algorithm that classifies images into classes (normal tissue, adenoma, adenocarcinoma). We’ve decided on a set of features to extract from each image in order to train and use a classifier (using the machine learning approach).
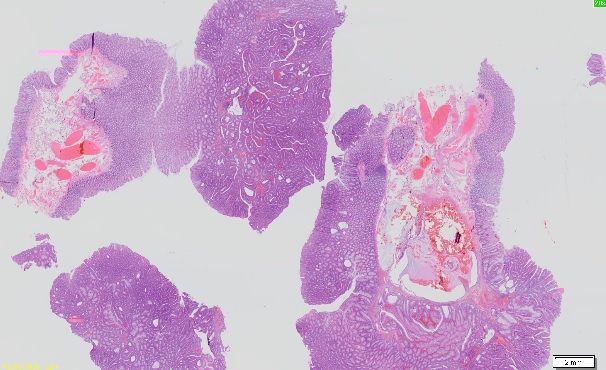
This project extend a previous project done in 2012. The problem domain is images that are the digital scanning of H&E stained tissues taken from the colon. A human pathologist expert segments the images into regions with the one of the following classi cation: normal tissue, adenoma (almost cancerous) and adenocarcinoma (cancerous).
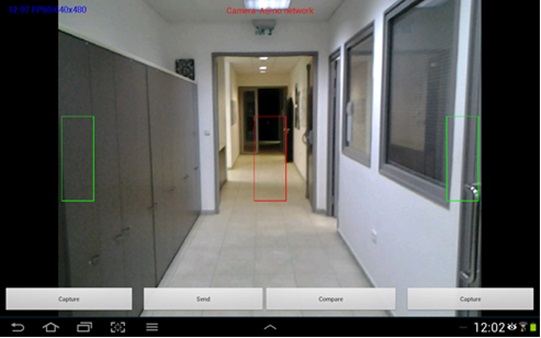
One of the security field related problems is a person re-identification via security cameras. In general, an object re-identification and in particular a person re-identification process faces a few challenges such as low resolution cameras and illumination changes. Therefore, a unique algorithm which overcomes those difficulties was developed.
In my work I have implemented this algorithm with C++ opencv and developed an android application which uses it.

The goal of this project is to create a sparse 3D reconstruction of a scene from a series of images of it.

Developing and implementing an android application that assists the user in placing the camera in an optimal position for scanning a document.

The method works by recognizing QR codes and display relevant advertisement. Implement an application which allows smartphone users to receive advertisements from android smartphone’s camera in augmented reality environment.
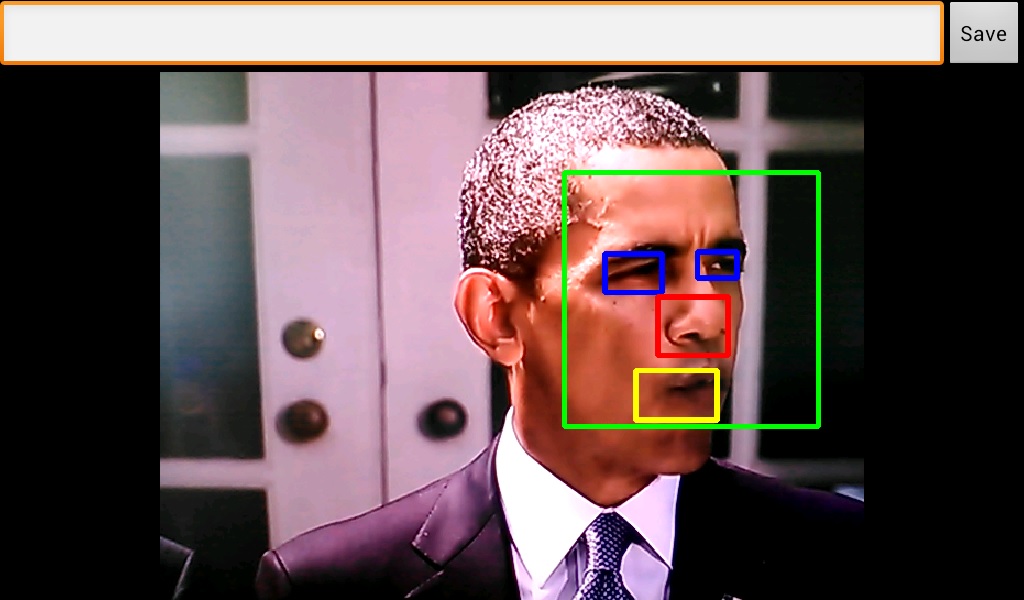
Our goal was to create a fully operational mobile application which could detect, recognize and track human faces. In order to do that, we have decided to use the Android platform combined with the opencv library. The development of the application was made on Qualcomm MSM8960 mobile device which run a 4.0.3 Android OS. In addition to the application we have built, we also did a research about how well we can use LDA and PCA in order to recognize faces and also about the use of LDA in order to do basic pose estimation.

Today a lot of people have a high probability to fall due to disease or old age. Those people need constant supervision which is very uncomfortable and expensive. In this project we’ve designed a fall detection algorithm that uses color and depth pictures from a Kinect camera. The robot is very user friendly and its purpose is to follow a person wherever he goes and when the person falls, the robot detects that and screams “Mayday!” for help. The fall detection algorithm uses information processing made by the follow algorithm.
In recent years there is a growing interest in detection of moving objects from aerial camera. For example, in Wide Area Airborn Surveillance (WAAS) huge images taken from unmanned aerial vehicle (UAV) are used to detect and track cars over a large area, i.e. entire city.
In this project we will implement algorithms for object detection is such scenarios.

With the high precision that is required during a surgery it may be almost impossible for a human eye to reach high enough precision based on an image taken of the organ or a specific area. The Surgery Simulation was built to overcome this obstacle using image proccessing techniques. Given two 2-dimensional images the application will allow us to mark points on the images and after analyzing the input the robot will move towards the exact points on the organ/area marked on the images and proceed with the needed procedure.
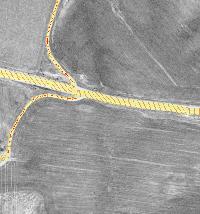
We would like to detect roads in aerial photos by using ridge detection. Due to different road widths, we would like to detect ridges in different scales. In [1] T. Lindeberg (1996) proposed a scale-space ridge detection with automatic scale selection by using Gaussian derivatives. We propose a faster approach that approximates Lindeberg’s solution, plus some additions.

Change-detection methods in video streams have varies applications in health monitoring, video surveillance, and quality control systems. These methods’ goal is to find objects of interest in an image sequence. For this purpose, it is common to detect objects by comparing new images with a representation of the background scene. In order to do so, one has to model the background first. Using machine learning algorithms it is possible to try and learn the background model from a sample of the scene. One of these learning methods is the “One Class SVM.”
In this project we use a blocked-based approach (meaning we divide each frame in a video to several blocks) in order to learn and model the background in a video using one class SVMs, thus detecting anomalies. We test several feature extraction methods, as well as probabilistic methods to estimate whether a change occurred or not. Experimental results may be found in the attached video.

With the advent of the Internet it is now possible to collect hundreds of millions of images. These images come with varying degrees of label information. Semi-supervised learning can be used for combining these different label sources. However, it scales polynomially with the number of images. In this work we utilize recent results in machine learning to obtain highly efficient approximations for semi-supervised learning that are linear in the number of images. This enables us to apply semi-supervised learning to a large database of images gathered from the Internet.
In our project we have implemented one of the new and the promising algorithms that can be found in the computer science community.
This Algorithm is taken from the SSL (Semi Supervised Learning) field. It uses a small amount of classified data to classify a large data base effectively.
In this project the students have implemented an algorithm for multiple target tracking. Graph algorithms are used for efficient computation of association and tracking problems.

Winner of the Amdocs excellent project award for 2010!
In this project we implemented background objects identification using their texture and color features. We used a feature vector composed of HSI color histograms, edges direction histogram and statistics of a grey-level co-occurrence matrix. We used an SVM classifier and we found its optimal parameters. We also introduced an improved feature vector that positively influenced the accuracy rate. In addition, we implemented a whole region classification by using weighted voting of the patches contained within. This project was then incorporated into a larger research in which a global context in the image was also used.
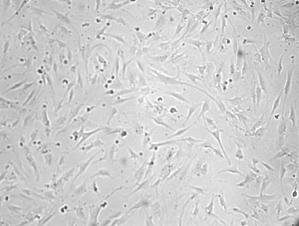
Some routine medical tasks may be automated to increase their efficiency and diminish their dependency on the human factor. One of such tasks is cell counting. In medical research hundreds of gray-level cell images are taken in order to count them manually. In a typical image, e.g. image 1, there are tens of cells. Nowadays a researcher has to count these cells manually, which is a monotonous time consuming procedure. A computerized automatic cell counter is essential to simplify and standardize this task.

This project uses video image processing in order to detect motion and analyze it so people entering or leaving will be counted. The program will first ask the user to choose the area on the screen where the image processing will take place. After that two counters will indicate the number of people who entered the area and the number of people who left the area. A third counter indicates the accumulated total of people in the room (number of people who left the area subtracted from the number of people who entered).
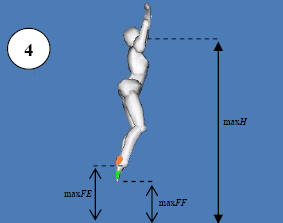
A tool to analyze several coordinative tests using of computer vision. today, all of these tests are being measures manually using stopwatches and other measuring instruments, and thus have a large tendency for error. It also has a strong infrastructure thus allowing future expansion of the system to new tests and ideas.
The SAVion software (Sports Analysis by computer Vision) was developed as a project in intelligent systems and advanced programming in the Technion’s ISL (Intelligent Systems Laboratory), Haifa.
The project was brought forth by Dr. Mark Wertheim from the Wingate institute. Dr. Wertheim proposed to use computer vision to analyze several coordinative tests, and explained that such a system can widely contribute to the efforts of all sports trainers.
Even today, all of these tests are being measures manually using stopwatches and other measuring instruments, and thus have a large tendency for error.
The SAVion software is a tool to analyze some of these tests, using a digital camera and a computer, using which it measures the needed parameters. It also has a strong infrastructure thus allowing future expansion of the system to new tests and ideas.
The project was developed under the supervision of Prof. Alfred M. Bruckstein, the guidance of Eliyahu Osherovich and technical support by ISL’s chief engineer Ronen Keidar.
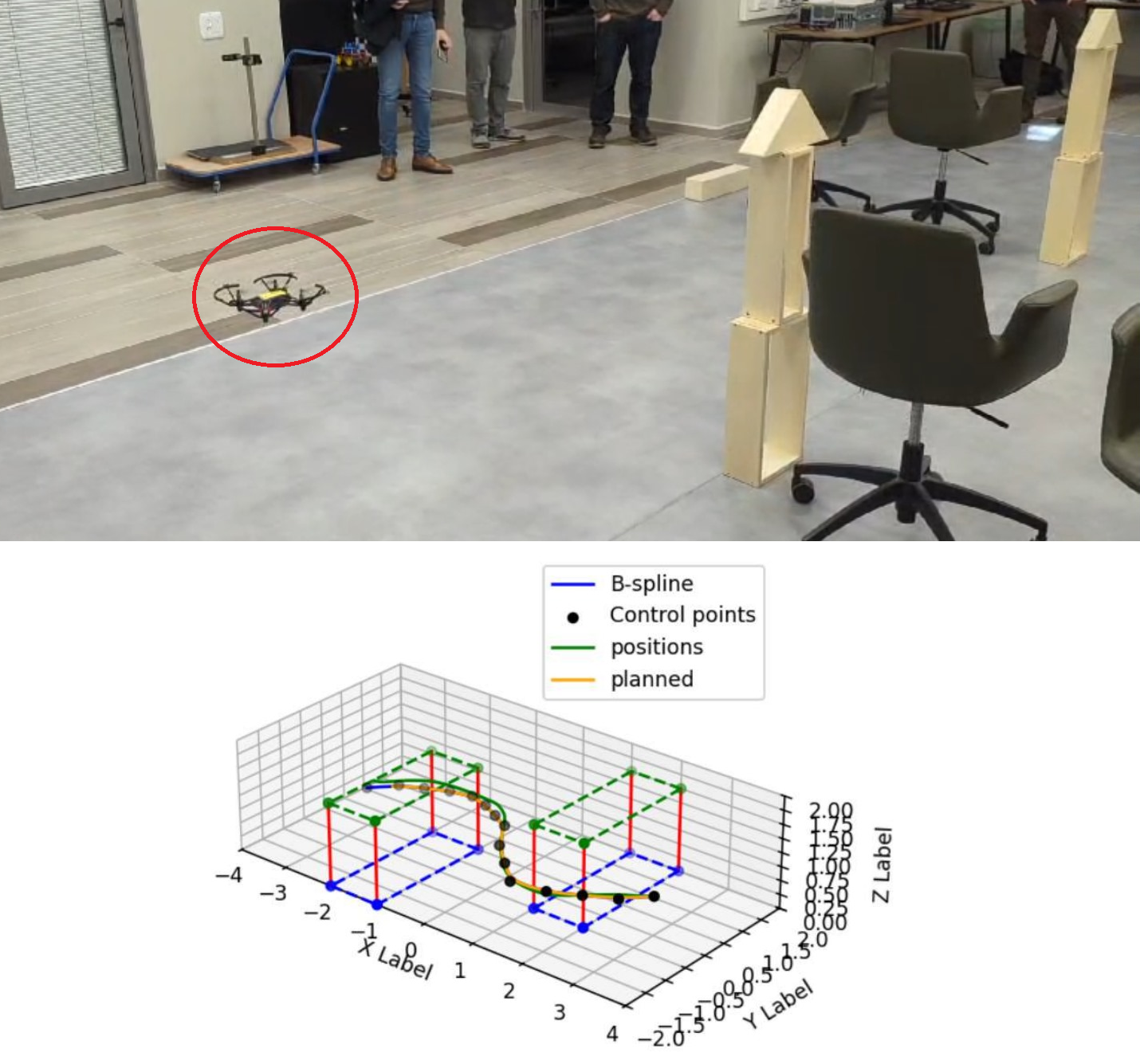
Unmanned Aerial Vehicles (UAVs) are increasingly used in diverse applications such as photography, delivery, and search-and-rescue. Traditional path planning methods, like A*, often produce discrete, sharp-angled routes that are inefficient and hard for drones to follow smoothly. In this project, we design an end-to-end system for the DJI Tello drone that combines spline-based path planning with a dedicated flight control mechanism. The path planner generates short, continuous, and obstacle-avoiding trajectories, while the control system enables the drone to track them with minimal error at high speeds.

This project is a part of a bigger project. The main objective of the project is to land a quadcopter on a moving target, using the image stream form the camera, mounted on the quadcopter.
The objective of this part of the project is to extract the angles of the taken image, which represents the position of the quadcopter in the world, with respect to the target in real world. This way, the quadcopter will be able to determine its next step, in order to approach the target.

This project objective is to develop an Android application which implements the STC on-line algorithm as developed and shown in [1]. Our project’s goal was to implement an optimal navigation application of unknown bounded planar, on an Android device along with solving the problem of controlling a mobile robot in real-time. We achieved those challenges by utilization of the device’s camera, for getting input on the neighborhood environment, and avoiding obstacles. As well, we used a IOIO platform, which is attached to the robot, to manage and control the robot movement. We produced an Android application thats implements the on-line STC algorithm, and communicate with the IOIO board, sending it movement commands accordingly.

The goal in this project was to come up with an algorithm based on a somewhat cheap accessory one can attach to a robot and determine the distance to an obstacle. This accessory is a camera which can be found anywhere nowadays from mobile phones to tablets and wearables and standalone cheap cameras which can cost no more than $5.

Autonomous Quadcopters are used to different purposes where they are required to navigate from a starting point to a destination point in its area. Thus, a GCS (Ground Control Station) should have information about local and target positions of the UAV.

With the significant growth of moving camera platforms like smartphones, robots and vehicles; a large portion of the video content is captured by moving cameras, and there is vital need for algorithms that isolate “interesting” objects in the captured videos. These “interesting” objects are often moving objects.
The main challenge in this domain is distinguishing the motion induced by moving the camera itself, from the motion induced by the moving objects.

In many tasks a mobile robot is required to navigate from any initial position to a desired position in its environment. This kind of task will require a global localization technique that allows the robot to operate without prior knowledge about its position and recover from odometry errors. Thus, the representation of the target position has to provide enough information for global localization. Such a representation should be robust with respect to minor changes in the environment.
Prevalent approaches to the navigation problem are model-based navigation and appearance-based navigation. Model-based approaches rely on knowledge of a 3D model of the environment. The localization is then performed by matching the global model with a local model deduced from sensor data .The model-based approaches require that either a map of the environment be provided, or that it be built by the robot. The latter is usually termed SLAM (Simultaneous Localization and Map Building).
The appearance-based approach does not require a 3D model of the environment. It has the advantage of working directly in the sensor space.
Our work is in the domain of the appearance-based approach. The goal is to implement [1] for an autonomous robot given a small set of images: these are taken in the preparation stage, with the robot’s camera, by the user in order to describe the environment. The positions from which the images were taken are the target locations.
Each image represents the position and orientation from which it was taken. Each image defines a region in the configuration space from which the image can be matched.
In the learning stage the robot autonomously explores the environment, locates the targets, and builds a graph of the paths between them. The exploration is driven by the coverage problem. After the learning stage the robot can navigate to any target in the environment from any position using the graph.

מטרת הפרוייקט הינה הרצת אלגוריתם ניווט של רובוט למטרה מוגדרת מראש, בעזרת כלים ויזאוליים בלבד. תנועת הרובוט מתבצעת על גבי משטח מישורי, בחדר שלא מופה מראש.
הרובוט מקבל כקלט תמונת מטרה שצולמה מנקודת המטרה, אליה אמור הרובוט להגיע. בעזרת מצלמה המותקנת על גבי הרובוט, הרובוט מצלם תמונות תוך כדי הניווט. בעזרת תמונות אלו, ועל בסיס השוואה בין תמונה שנלקחה בצעד מסוים, למול תמונת המטרה, הרובוט מחשב את צעד ההתקדמות הבא לעבר המטרה.
החישוב נעשה בעזרת essential matrix בעלת מבנה ייחודי המתאים לתנועה מישורית. מבנה ייחודי זה מאפשר לבנות את ה-essential matrix על בסיס התאמת שתי נקודות בלבד (2-point correspondence ).
במימוש הפרוייקט השתמשנו ברובוט של Pioneer, מצלמת IP של AXIS .
השליטה ברובוט מבוססת כולה על: ROS – Robot Operating Systems , תוך שימוש ב-nodes ששולטים על חלקיו השונים של האלגוריתם.
– Perform real time tracking using android smartphone
– The target is red colored paper, it is distinguished solely by its color
– The Smartphone controls a Rover5 robot using the microcontroller IOIO board

For any mobile device, the ability to navigate in its environment is one of the most important capabilities of all. Robot navigation means its ability to determine its own position in its frame of reference and then to plan a path towards some goal location. In order to navigate in its environment, the robot or any other mobility device requires representation i.e. a map of the environment and the ability to interpret that representation.

A quad-rotor type X-3DBL UFO helicopter is used in our project. The project goal is to learn the quad-rotor dynamics and create a control algorithm that will stabilize its orientation. The quad-rotor is initially equipped with a 3DOF gyro . In addition to the gyro, an Xsens IMU added.
The IMU contains 3DOF gyro, 3DOF accelerometer , barometer and GPS unit. With the help of the IMU and with the measurements of the platform acceleration and rate in all 3 axis we succeed estimating the platform angles, controlling and stabilizing the platform orientation. The quad-rotor can receive a reference input to the platform angles : psi, theta, phi; and successfully track the reference without any errors. The communication to the platform is with a communication box that has 2 controlling channels: 1. Manual control – wireless communication that controls the platform. 2. Auto control – control with the MATLAB code, this option is wired and not wireless because of the high sampling rate of the IMU (512Hz).
Our project uses both color and depth images taken from “Kinect”- a popular depth camera, to segment the picture and find all the objects in the scene. The depth channel enables us to find the edges of objects that have similar colors, while the color channel helps us to distinguish between adjacent objects. After the preceding process, we use a classifier, which is based on SVM (Support Vector Machine), to identify each person in the scene and build a color histogram for him.
Finally we choose the person that his histogram has the highest similarity to the one of the tracked person.
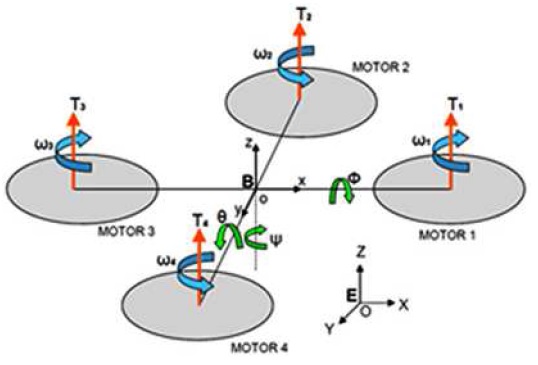
This report presents a Quad-rotor simulation built for the Intelligent Systems Lab at the Computer Science Faculty at the Technion IIT.
Different projects at the lab use quadrotors as platforms for research, mainly in the computer vision aided navigation field. A tailor made quadrotor simulation responds to the need to fully understand the system dynamics, the control laws and sensors modeling, in order to assess the algorithms developed in the frame of the research prior to flight testing.